prérequis : bases en probabilités, softmax et notion de "token" pour un LLM.
Cet article est basé sur ce papier
But
Un LLM est un modèle entraîné spécifiquement pour écrire le texte le plus probable, ou en tout cas le plus attendu par l'utilisateur, à partir d'un prompt.
Malheureusement, les LLM sont utilisés massivement pour différentes tâches qui menacent le bien commun, comme:
- la rédaction de devoirs sans par les élèves sans aucune réflexion
- l'écriture de mails de phishing
- l'écriture de posts sur les médias sociaux pour encourager la mésinformation
Dans ces contextes, il est important de pouvoir vérifier qu'un texte a été écrit ou non par une machine. Pour cela, on modifie le comportement du modèle en faisant en sorte que la modification soit imperceptible pour un humain. C'est ce qu'on appelle le watermarking (filigrane en français).
Stratégies
Il existe différentes approches pour attaquer ce problème. Chaque approche est un compromis entre ces deux extrêmes:
Modification mineure
La distribution de probabilité conditionnelle de chaque token est peu modifiée. On obtient des textes très cohérents, surtout pour les textes très prédictibles ("Maître corbeau sur un arbre perché ..."). Cependant, il faut un texte très long pour identifier si il a été écrit par un LLM ou non.
Modification majeure
La distribution de probabilité conditionnelle de chaque token est beaucoup modifiée. On peut identifier si un texte a été écrit par un LLM au bout de quelques mots, mais les textes sont moins cohérents (surtout pour les textes très prédictibles, qui seront modifiés et donc repérés par l'humain).
Red-words
Cette approche est très simple: on associe à chaque token une liste de tokens autorisés (verts) et une liste de tokens interdits (rouges) choisis aléatoirement.
Pour générer un texte, on regarde le dernier token (en position *) et on génère le token le plus probable parmi les tokens autorisés pour .
Note
Cela revient à interdire la moitié des digrammes, c'est à dire des suites de tokens de longueur 1
On suppose d'abord qu'il y a autant de tokens rouges que de tokens verts, distribués de manière uniforme.
Supposons que l'on génère un texte de tokens à l'aide de ce modèle.
Un détecteur regarde le texte en notant à chaque fois si un token est suivi d'un autre dans la liste verte ou dans la liste rouge. Si tous ou presque sont verts, il peut conclure que le texte est généré par le modèle. Si la moitié est verte et la moitié est rouge, il peut conclure que le texte est généré par un humain.
La probabilité de se tromper avec ce genre de détecteur est de l'ordre de
Mais certains enchaînements de mots sont tout simplement interdits: par exemple, "camion" pourrait avoir comme mot rouge "poubelle", et donc le modèle serait incapable de générer un texte sur les camion-poubelles.
Meilleur choix des mots interdits
Pour améliorer l'approche précédente, on pourrait ne choisir un mot vert que si il est plus probable qu'un certain seuil.
Par exemple, dans la phrase "Le président de la France est Emmanuel ...", le mot "Macron" est extrêmement probable. Si le mot "Macron" est rouge, on va alors choisir le mot vert le plus probable (disons "Kant"), ce qui n'est pas du tout cohérent.
Cette approche a l'avantage de ne pas modifier ou presque les texte prédictibles (dits de faible entropie).
Mais cette approche est difficile à analyser mathématiquement, le choix du seuil n'est pas facile.
Une approche plus satisfaisante mathématiquement est décrite dans la partie suivante
Soft-choice
Dans cette approche, on va rendre moins probable tous les digrammes rouges, et rendre moins probable tous les digrammes verts. On veut la propriété suivante: si est très probablement suivi par mais que est rouge, reste probablement suivi par .
Une manière de garantir cela est d'utiliser une fonction "softmax".
Étant donné tous les tokens précédents, on peut mathématiquement attribuer à chaque token un score tel que la distribution de probabilité proposée pour le prochain token est
On va ajouter une pénalité pour tous les mots rouges (autrement dit un bonus pour tous les mots verts)
Notons le token précédent dans le texte. On pose si est rouge et si est vert.
On a alors
Distribution originale:

Distribution modifiée:

Formalisation
Soit les tokens de la question posée au LLM.
On note la variable aléatoire correspondant à la réponse au prompt par le LLM sans watermark, et sa réponse avec watermark (de longueur )
Enfin, on note le nombre de digrammes verts dans
Pour décider si une complétion a été faite par un LLM, on regarde si est supérieur à un seuil. Pour déterminer ce seuil, on utilise l'inégalité de Bienaymé-Tchebychev.
Il faut alors déterminer la variance et l’espérance de .
Celles-ci vont dépendre du prompt. Par exemple, si le prompt est "écrit 100x le mot bonjour", il y a une seule réponse probable. Si le digramme "bonjour bonjour" est vert, alors . Sinon,
Une propriété souhaitable est : on veut que la complétion avec watermark ne soit pas surprenante (ou en tout cas pas trop surprenante) que celle sans watermark.
Il y a donc un compromis entre la sensitivité du détecteur et la qualité de la réponse souhaitée. On a pu mesurer ce compromis sur un jeu de données (en haut plus de sensitivité, à droite meilleure qualité):
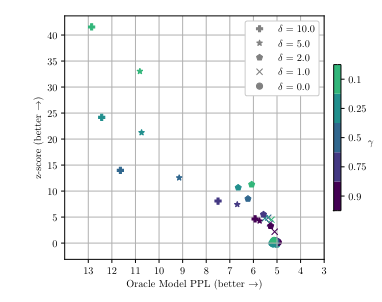
Empiriquement, on a montré que l'on peut choisir un seuil indépendant du prompt qui permet d'identifier si une suite de 128 tokens est générée par le LLM avec watermark 98% du temps. Les 2% d'erreurs sont causée par des prompts dont les réponses sont presque certaines (entropie faible).
Limites
On peut lister 2 vecteurs d'attaque majeurs:
L'attaque par instructions et effacement
Dans cette attaque, on demande par exemple au LLM "Ajoute un emoji un mot sur deux". Ensuite, il suffit de supprimer tous les emojis générés, pour obtenir un résultat qui n'a aucune chance d'être watermarked.
Ce vecteur d'attaque peut être évité en interdisant au LLM d'effectuer ce genre d'actions, mais savoir comment forcer un LLM à ne pas avoir un comportement est encore très difficile (voir RLHF).
L'attaque par reformulation
Dans cette attaque, on génère un texte watermarqué avec un LLM, et on utilise un autre LLM pour reformuler l'information.
Étant donné que beaucoup de modèles sont open-source, ceci peut se faire très facilement. D'autant plus que reformuler est une tâche très simple pour un LLM, et on perd peu de qualité d'information.
C'est toute la difficulté associée aux modèles open-source.